Sklearn Kütüphanesi Kullanarak K-Means Kümeleme Algoritması
Makine öğrenmesindeki öğrenmeler gözetimli, gözetimsiz ve takviyeli öğrenme olarak ayrılabilir. Gözetimli öğrenmede sınıflandırma ve regresyon çalışmaları yer alır ve hedef değerleri algoritmaya verilerek makine öğrenmesi sağlanır. Gözetimsiz öğrenmede ise en sık çalışılan konu kümeleme çalışmasıdır. Gözetimsiz öğrenmede ayrıca özellik çıkarımı (Feature Extraction), birincil etken analizi (Principle Component Analysis), ya da aykırı veri analizi (Outlier Analysis) gibi çalışmalar bulunur. Bu yazıda gözetimsiz öğrenmedeki kümeleme çalışmalarına örnek olarak K-Means algoritması ve uygulaması gösterilecektir.
Gözetimli ve Gözetimsiz Öğrenme

Sınıflandırma grafiğinde kırmızı ve daire şeklinde noktalar görülebilir. Başlangıçta bu noktaların sınıfları ya da renkleri ve şekilleri makineye veriliyor. Ardından makinenin bunları öğrenmesi ve yeni gelecek verileri bu öğrenmeye göre sınıflandırması isteniyor. Sınıflandırma çalışmasında sınıfları birbirinden ayıracak en uygun çizgi belirlenmeye çalışılır. Bu çizgiyi çizdikten sonra veri setini ne kadar iyi sınıflandırdığımız daha sonra eğitim ve test setleri üzerinden hesaplanır. Diğer grafikte sadece kırmızı ve daire şeklinde noktalar olduğu görülür. Bu veri setinde gruplar oluşturulmak istenirse kümeleme algoritmalarını kullanılabilir. Kümeleme algoritmaları veri setindeki benzer yapıda bulunan verileri bir araya getirerek gruplar oluşturmaya çalışır. Veriler arasındaki Öklid uzaklığa, Minkowski uzaklığa, Manhattan uzaklığa bakarak verilerin ne kadar benzediğini/benzemediğini hesaplamaya çalışır.
Kümeleme Analizinde Sorulacak Sorular
Kısaca kümeleme algoritmasında şu sorular başlangıçta sorulur.
- Gruplama denklemi olarak hangi verilerin ne kadar benzediğine nasıl karar vereceğiz?
- Kümeleme sonucu ne kadar doğru, ne kadar hızlı verimli?
- Veri içerisinde ne kadar küme olacağını düşüneceğiz?
Kümeleme Algoritmalarının Örnek Uygulama Alanları
- Benzer özellikteki müşterilerin belirlenerek reklam kampanyalarının müşteri özelliklerine göre ayrı belirlemek
- İnternetteki benzer dokümanları gruplamak (Benzerlik raporları gibi)
- Benzer özellikteki protein dizilimlerinin ortaya çıkarılması (COVID19 hangi virüsün protein dizisine benziyor gibi)
- Benzer özellikteki şarkıları bir araya getirerek bir kategorizasyon yapmak
K-Means Kümeleme Algoritması
K-means kümelemede en çok kullanılan algoritmadır. Verinin kesin bir şekilde hangi kümeye ait olduğunu söyler. Yani bulanık ya da kaba küme olduğunu belirtmez. K-means algoritması önce veriyi k adet kümeye böler. Kümelerin orta noktalarını(centroid) bulur. Her bir veriyi bölünen kümelerden verinin en yakın olduğu kümesine atar. Burada hangi uzaklık ölçüsü kullanılacaksa ona göre bir hesaplama gerçekleştirilir. K-means algoritması bulunan kümedeki orta noktanın diğer orta noktalardan olabildiğince uzak olmasını bir kümenin içerisindeki verilerin ise olabildiğince yakın olmasını amaçlar. Aşağıda akış şeması verilmiştir.
K nokta sayısı kadar orta nokta belirle
Tekrarla
Her bir noktayı en yakın orta noktanın olduğu kümeye dahil et.
Tekrar orta noktaları hesapla
Orta noktalar değişmeyene kadar devam et
K-Means Algoritması Uygulaması
Scikit learn kütüphanesi içerisinde K-Means gibi birçok kümeleme algoritması vardır. K-means algoritması uygulamasını biraz daha kolay anlayabilmek için iris veri seti üzerinde ele alalım.
# Gerekli kütüphanelerin çağrılması
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import cluster
plt.style.use('ggplot')# Veriseti
iris = load_iris()
X, y = load_iris(return_X_y=True)# ilk 2 özelliğin serpilme grafiği
plt.scatter(X[:,0], X[:,1], c=y)
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1])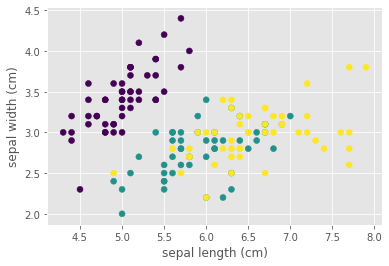
# 3 kümeye ayıralım
kmeans = cluster.KMeans(n_clusters=3, random_state=42)
kmeans.fit(X)# bulunan 3 kümenin orta noktası
kmeans.cluster_centers_.round(2)array([[5.9 , 2.75, 4.39, 1.43], [5.01, 3.43, 1.46, 0.25], [6.85, 3.07, 5.74, 2.07]])
# Sonuç kümeleri
kmeans.labels_array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 0, 0, 2, 2, 2, 2, 0, 2, 0, 2, 0, 2, 2, 0, 0, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 0])
# Kümeleme Sonuçları
plt.scatter(X[:,0], X[:,1], c=kmeans.labels_)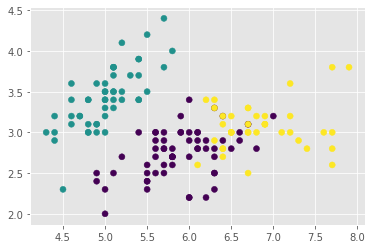
# Gerçek sınıfların olduğu grafik
plt.scatter(X[:,0], X[:,1], c=y)
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1])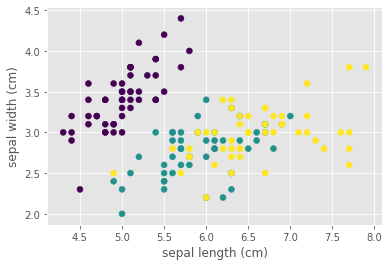
Videosu
Kaynaklar
- Akküçük, Ulaş. “Veri madenciliği: kümeleme ve sınıflama algoritmaları”. İstanbul: Yalın Yayıncılık 18 (2011).
- Han, Jiawei, Jian Pei, ve Micheline Kamber. Data mining: concepts and techniques. Elsevier, 2011.
- Kantardzic, Mehmed. Data mining: concepts, models, methods, and algorithms. John Wiley & Sons, 2011.
- Sumathi, Sai, ve S. N. Sivanandam. Introduction to data mining and its applications. C. 29. Springer, 2006.
- Tan, Pang-Ning, Michael Steinbach, ve Vipin Kumar. Introduction to data mining. Pearson Education India, 2016.
- Towards Data Science. “Towards Data Science”. Erişim 29 Mart 2020. https://towardsdatascience.com/.VanderPlas, Jake. Python Data Science Handbook. OReilly Media. Inc, 2017.
